
-----------------更新日志-----------------
20:33 2017/1/28 提供MATLAB生成loss曲线的方法
-----------------更新日志-----------------
如果遇到一些问题,可以在找下是否有解决方案。本文内容主要分为两部分,第一部分介绍基于caffe的回归分析,包括了数据准备、配置文件等;第二部分介绍了在MATLAB上进行的可视化。(话说本人最近有个课题需要做场景分类,有兴趣可以共同探讨一下)。
Preparation
预装好caffe on windows,并编译成功MATLAB接口。
通过caffe进行回归分析
通过caffe进行回归分析,在实验上主要分成HDF5数据准备、网络设计、训练、测试。该实验已经有网友做过,可以参考:
或者查看转载的副本(http://blog.csdn.net/xiaoy_h/article/details/54731122)。但不同的是,本文在实验中某些必要的环节均通过MATLAB实现,而不是。下文仅对不同的内容进行介绍。
通过MATLAB准备HDF5数据
MATLAB是正经的MATLAB,比如你的数据含有35个输入变量,共10000个 样本;先在MATLAB中创建一个变量,将数据(在此之间别忘了先做scaling)拷贝进去,将得到一个10000x 35的变量,当然标签变量就是10000 x 1的啦;最终得到train_x(10000 x 35)、train_y(10000 x 1)、test_x(600 x 35)、test_y(600 x 1)共四个变量,将他们保存到mat文件中,比如data.mat文件。
然后,通过如下脚本实现h5数据的转换(该脚本修改自CAFFE_ROOT\matlab\hdf5creation\目录下的demo.m):
%% WRITING TO HDF5filename = 'train.h5';load 'data.mat';num_total_samples = size(train_x,1); %获取样本总数data_disk = train_x';label_disk = train_y';chunksz = 100; %数据块大小created_flag = false;totalct = 0;for batchno=1:num_total_samples/chunksz fprintf('batch no. %d\n', batchno); last_read = (batchno-1)*chunksz; % 在dump到hdf5文件之前模拟内存中放置的最大数据量 batchdata = data_disk(:,last_read+1:last_read+chunksz); batchlabs = label_disk(:,last_read+1:last_read+chunksz); % 存入hdf5 startloc = struct('dat',[1,totalct+1], 'lab',[1,totalct+1]); curr_dat_sz = store2hdf5(filename, batchdata,batchlabs, ~created_flag, startloc, chunksz); created_flag = true; %设置flag为了只创建一次文件 totalct = curr_dat_sz(end); %更新数据集大小 (以样本数度量)end%显示所存储HDF5文件的结构体h5disp(filename);%创建HDF5_DATA_LAYER中使用的list文件FILE = fopen('train.txt', 'w');fprintf(FILE, '%s', filename);fclose(FILE);fprintf('HDF5 filename listed in %s \n','train.txt'); 如上是训练集的h5格式生成方式,测试集的如法炮制一个脚本就行啦。至此,将得到四个 文件,分别是train.h5,test.h5,train.txt,test.txt,前面两个为数据集文件,后面两个为数据集文件的路径描述文件,如 果每个phase存在多个数据集的话只要在一个路径描述文件里列出即可。
网络设计
网络设计是能否得到有用模型的关键之一,可以参考一些资料,并根据自身数据的特点合理设计。本文采用如下简单的网络进行介绍:
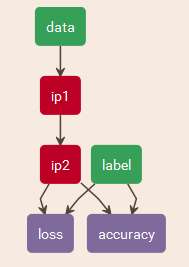
训练和测试
一些主要的步骤在之前提到的博客中都有描述,这里讲一个trick—如何获取训练时的loss曲线。
首先,找到CAFFE_ROOT\src文件夹里的common.cpp文件并修改里面的内容:
1、添加头文件#include<direct.h>
2、定位voidGloballnit函数,在::google::InitGoogleLogging(*(pargv)[0]);下一行添加如下代码:
_mkdir("./log/");FLAGS_colorlogtostderr =true; //设置输出到屏幕的日志显示相应颜色//如下为设置各类日志信息对应日志文件的文件名前缀google::SetLogDestination(google::GLOG_FATAL,"./log/log_error_");google::SetLogDestination(google::GLOG_ERROR,"./log/log_error_");google::SetLogDestination(google::GLOG_WARNING,"./log/log_error_");google::SetLogDestination(google::GLOG_INFO,"./log/log_info_");FLAGS_max_log_size = 1024; //最大日志大小为 1024MBFLAGS_stop_logging_if_full_disk =true; //磁盘写满时,停止日志输出 修改完成后别忘了保存并重新编译caffe.exe,在之后的训练中可在CAFFE_ROOT\log下找到训练日志。
在获得了训练日志后,比如文件名为log_info_20170116-163216.9556,有两种方法可以得 到loss曲线图,一种caffe本身支持的但是必须有Python环境,另一种通过在MATLAB里用正则实现(没有Python环境的同学们有福 了)。分别如下:
(1)将日志复制到CAFFE_ROOT\tools\extra目录下(可以看到同目录下的py程序),接着在该目录下打开命令行,并运行命令:
md logconvset logfile=log_info_20170116-163216.9556python parse_log.py %logfile% ./logconvren logconv\%logfile%.train %logfile%.csvpause
然后py程序会将日志转为csv文件,在excel表格中即可绘制loss曲线图:
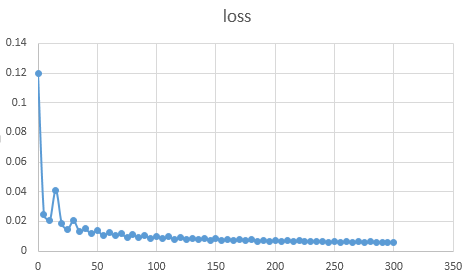
(2)通过如下代码进行提取,可以保存成parse_log.m文件,正则表达式语法和Python的基本相同,稍微改动了一下,功能较caffe提供的有所阉割,毕竟有的暂时用不到。
function []= parse_log(filename)regex_iteration_str = 'Iteration (\d+)';regex_train_output_str = 'Train net output #(\d+): (\S+) = ([.\deE+-]+)';FILE = fopen(filename);FOUT = fopen(sprintf('%s.csv',filename),'w');fprintf(FOUT,'iter,accuracy,loss\n');plotdata=[];while ~feof(FILE) aline = fgetl(FILE); rescell = regexpi(aline,regex_iteration_str,'tokens'); if size(rescell,1)~=0; iteration = int32(str2num(rescell{1,1}{1,1})); end rescell = regexpi(aline,regex_train_output_str,'tokens'); if size(rescell,1)~=0; if str2num(rescell{1,1}{1,1})==0 accuracy = str2num(rescell{1,1}{1,3}); end if str2num(rescell{1,1}{1,1})==1 loss = str2num(rescell{1,1}{1,3}); plotdata(size(plotdata,1)+1,1) = iteration; plotdata(size(plotdata,1),2:3) = [accuracy loss]; fprintf(FOUT,'%d,%f,%f\n',iteration,accuracy,loss); end endendfclose(FILE);fclose(FOUT);figure,plot(plotdata(:,1),plotdata(:,2),'LineSmoothing','on');xlabel('iter'),ylabel('accuracy');figure,plot(plotdata(:,1),plotdata(:,3),'LineSmoothing','on');xlabel('iter'),ylabel('loss');end 最后,该程序会直接生成曲线图,画风大概是下面这样;当然了,生成的csv文件可以在excel里进行绘图的二次创作。
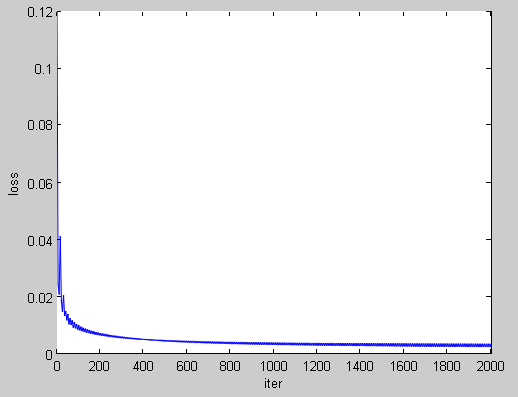
基于MATLAB的模型可视化
网络模型的可视化又可以分为权值可视化(有的人觉得偏置不重要,不过偏置量在有的时候非常重要)和特征图可视化,按照自身应用的需求可以设计不同的可视化样式。
在实验上,可视化的步骤分为deploy文件编写、通过MATLAB接口读取训练好的模型文件、按照自身需求输出权值可视化图和输入样本并生成特征图。
deploy文件编写
通过脚本得到deploy文件的方法网上已经有一些了:,不过貌似使用起来也挺麻烦的,不是通过输入直接输入train.prototxt文件来实现的。该方法有时候还没有直接手写来得简单粗暴:
从该博客内容可以得知deploy文件编写与train_test.prototxt不同的注意点大致如下:
1、*_deploy.prototxt文件的构造没有test网络中的test模块,只有训练模块
比如不能有如下之类的描述:
include{ phase:TRAIN/TEST }
2、数据层的写法更加简洁:
input: "data"input_dim: 1input_dim: 3input_dim: 32input_dim: 32
注意红色部分,那是数据层的名字,没有这个的话,第一个卷积层无法找到数据;接着的四个参数为输入样本的维度。
3、卷积层和全连接层中weight_filler{}与bias_filler{}两个参数不用再填写,因为这两个参数的值由已经训练好的模型caffemodel文件提供。
4、输出层的变化没有了test模块测试精度,具体输出层区别如下:
*_train_test.prototxt文件:layer{ name: "loss" type: "SoftmaxWithLoss" #注意此处与下面的不同 bottom: "ip2" bottom: "label" #注意标签项在下面没有了,因为下面的预测属于哪个标签,因此不能提供标签 top: "loss"}*_deploy.prototxt文件:layer { name: "prob" type: "Softmax" bottom: "ip2" top: "prob"} 两个文件中输出层的类型不一样,一个是SoftmaxWithLoss,另一个是Softmax。另外为了方便区分训练与应用输出,训练时输出是loss,应用时是prob(当然,叫别的名也行)。
如果后续在执行这一行(net = caffe.Net(model,'test');)MATLAB代码时程序直接崩溃了,那就是因为deploy文件中关于层的内容没有正确编写;而如果 在执行这一行(net.copy_from(weights);)代码时程序直接崩溃了,那可能因为deploy文件中关于神经元输入输出维数的参数没有 写对,比如在data层中input_dim: 3写成了input_dim: 1就会出错。
最后,可以参考下某个网络修改前后各层的对照(右边是deploy文件):
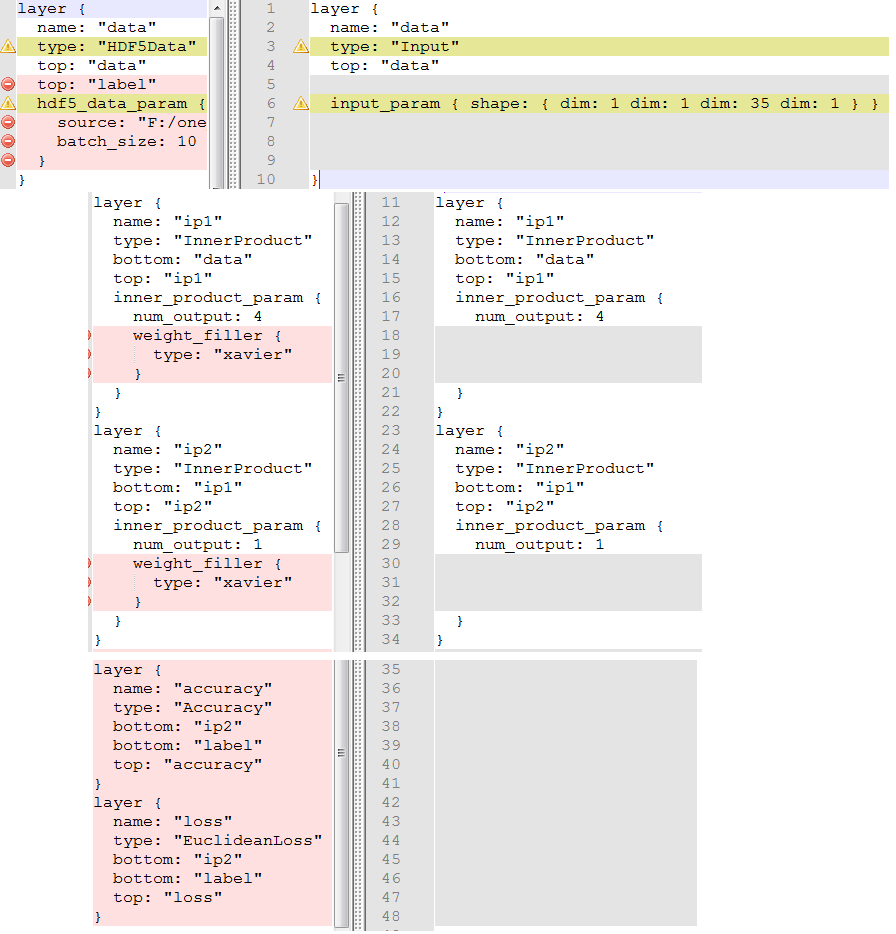
注意一下,本人在这里省去了prob层(一个softmax层),有时候分析网络模型有这个层是一种累赘,视具体情况可以去掉;同时,由于softmax层没有权值等参数,所以在导入MATLAB中时程序并不会崩溃。
通过MATLAB接口读取训练好的模型文件
如下代码实现了测试样本导入、网络导入和权值导入等:
load 'data.mat'; %加载样本数据caffe.set_mode_cpu(); %设置为CPU模式model = 'deploy.prototxt'; %模型-网络weights = 'snapshot/_iter_10000.caffemodel'; %模型-权值net = caffe.Net(model,'test');net.copy_from(weights); %得到训练好的权重参数
按照自身需求输出权值可视化图
上面已经完成好了权值等参数的导入,下面将首先获取层名,然后逐层可视化权值,废话不多说,直接上代码:
layernames = net.layer_names; %获取所有层名magnifys = 3; %卷积核放大倍数,用于可视化放大for li = 1:size(layernames,1)% disp(layernames{li}); if strcmp(layernames{li}(1:2),'ip') ||strcmp(layernames{li}(1:2),'fc') %fc层 %还没想好怎么plot elseif strcmp(layernames{li}(1:4),'data') %数据层,跳过 elseif strcmp(layernames{li}(1:4),'conv') %卷积层 weight = net.layers(layernames{li}).params(1).get_data(); bias = net.layers(layernames{li}).params(2).get_data(); %归一化 weight = weight-min(weight(:)); weight = weight./max(weight(:)); [ker_h,ker_w,prev_outnum,this_outnum] = size(weight); [grid_h,grid_w] = getgridsize(prev_outnum); for thisi=1:this_outnum weight_map = zeros(magnifys*ker_h*grid_h+grid_h,magnifys*ker_w*grid_w+grid_w); for gridhi=1:grid_h for gridwi=1:grid_w weight_map((gridhi-1)*(magnifys*ker_h+1)+1:gridhi*(magnifys*ker_h+1)-1,(gridwi-1)*(magnifys*ker_w+1)+1:gridwi*(magnifys*ker_w+1)-1)=imresize(weight(:,:,(gridhi-1)*grid_w+gridwi,thisi),magnifys,'nearest'); end end imwrite(uint8(weight_map(1:end-1,1:end-1)*255),sprintf('layer_%s_this_%d.bmp',layernames{li},thisi)); end elseif strcmp(layernames{li}(1:4),'pool') %池化层 %无参,不需要plot endend 上述代码中,注意getgridsize是用于确定卷积层中整张大图里卷积核排列的行列数,该函数可以自行发挥。
最后,由于回归分析网络需要结合具体的变量来解释权值图,故只能放一下lenet模型权值可视化的结果啦(只有conv层的,fc层需要结合具体变量):

输入样本并生成特征图
1、首先随意传入一个样本:
res = net.forward({test_x(1,:)});
注意传入的是一个cell,而不是常见的matrix。前向计算后,在网络各层就会产生特征图。
2、上文中我们都知道,权值数据的获取方式为:
weight = net.layers(layernames{li}).params(1).get_data();
而特征图的获取也类似,为:
featmap = net.blobs(layernames{li}).get_data();
其它代码与权值可视化基本相同,网友们可以自由发挥。
最后,由于回归分析网络需要结合具体的变量来解释特征图,故只能放一下lenet模型特征图可视化的结果啦:

